The Persistence Polyglot for Tiny Data and Big Data
Data storage used to be expensive and complicated. Now, as storage becomes more affordable, persistence polyglots are become a viable option for handling different data structures and quantities.
Thesis: Persistence polyglots make things simpler
Only a short time ago, the IT industry suffered from the limitations of Moore’s Law that limited data storage for applications. Storage technologies like relational databases and the underlying storage infrastructure were expensive and limited in their capabilities. This has been especially true in the areas of data storage related to large applications where, unless our teams had the endless financial ability to find new ways to overcome data storage complexities and limitations, IT teams were stuck using a single storage solution and find ways around its limitation.
The classic example is that of a common relational database and their underlying block storage systems. Up until recently, such relational data storage was the only game in town for application development. Most relational solutions cannot yet cleanly, simply and affordably handle things like document storage, key/value storage, relationship reification, big data, and much more. The limitations forced IT professionals (especially developers and engineers) to try and find ways to force the one relational database they could barely afford to maintain to behave like different storage types. It is a classic case of treat everything like a nail because you can only afford to own a hammer. This reality only drove the costs and complexities of the applications dependent on such relational storage solutions to be far higher than they really needed to be.
Enter the persistence polyglot
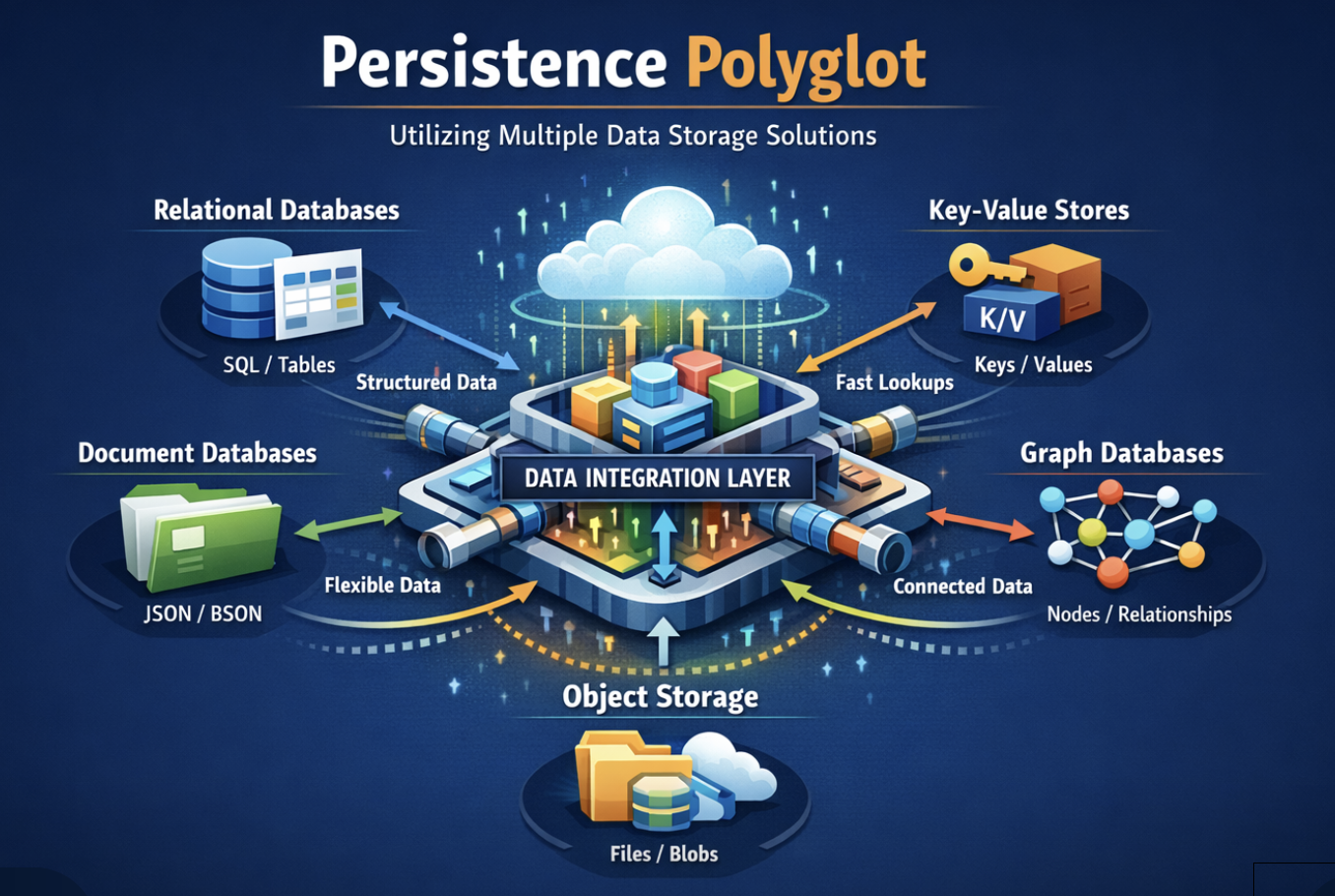
Persistence polyglots are a storage paradigm that consists of multiple different/heterogeneous storage types that handle different data needs. For example, one application can use different data and information storage solutions to solve different data storage needs:
-
Relational databases for highly structured relational data,
-
Document storage for unstructured documents,
-
Key-value stores for ultra-fast lookups and simple data access patterns,
-
Graph databases for highly connected data and relationship-heavy use cases,
-
Time-series databases for time-based data such as metrics and logs,
-
Object storage for large binary assets like images, videos, and files,
-
Etc.
As you explore these different types of storage, you’ll find that each specializes in different ways. Some specialize in dealing with highly structured data, others do well with semi-structured data, and others specialize in dealing with unstructured data (a.k.a. “raw data”).
This polyglot approach allows applications to leverage the strengths of each storage type rather than forcing all data into a single model, resulting in better performance, scalability, and alignment with specific business and technical requirements.
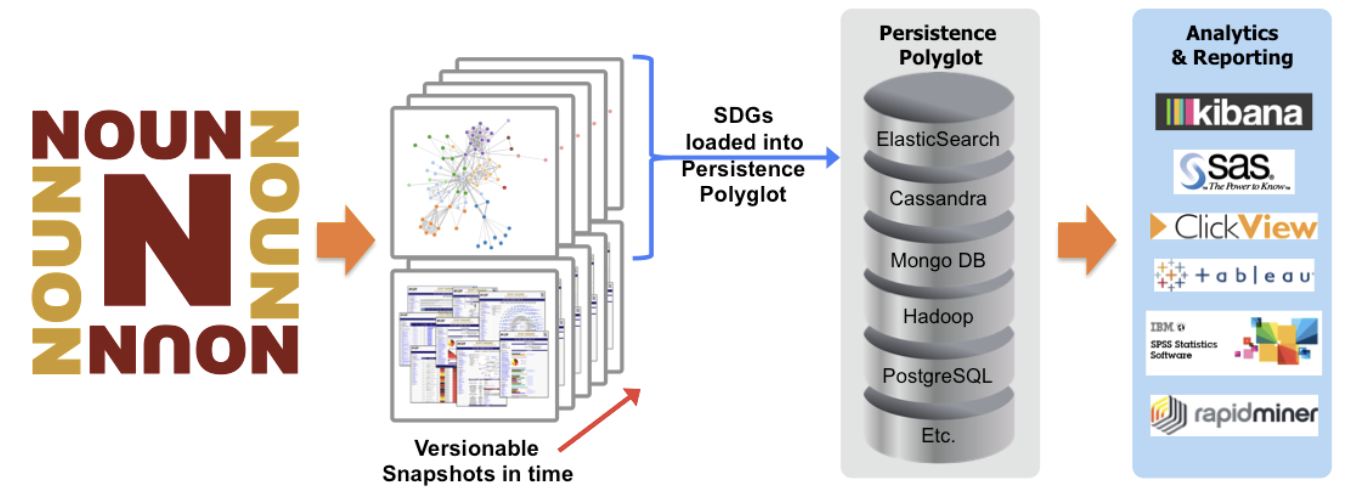
For example, our own internal NOUNZ data compiler takes advantage of such solutions, creating data sets that are targeted for different types of data and information stores. The reason for doing so is that downstream consumers of the data can now easily and quickly access the data they need in a format that is best suited for their consumption patterns. This helps keep data conversion costs and latency down.
Storage-related skills is a hurdle
Up until recently, the skills required to manage all the different types of data and information storage also became a blocker for most IT organizations. This is especially the case in smaller enterprises where the IT staff is limited and the skills need to be either highly focused on very specific business needs or more broadly focused on infrastructure-related areas.
However, this limitation will slowly disappear with the advancement of Cloud computing platforms.
Cloud platforms will make persistence polyglots common
The advancement of Cloud computing platforms like Amazon Web Service (AWS), Azure, and Google Cloud Platform (GCP), will only make access to these different types of data and information storage solutions easier and more affordable. This will especially become true as many of these storage solutions become commoditized as managed services that abstract backend infrastructure.
Conclusion: Consider persistence polyglots
As these new technologies develop, now might be a good time for your development and engineering organizations to look into leveraging persistence polyglots for your applications before making the complex and expensive commitment of making a square peg fit into a round hole. It may be easier, quicker, and more affordable to leverage storage solutions that allow using data and information in their more native forms.